
오늘날 기업은 중대한 과제에 직면해 있습니다. 경쟁력을 유지하기 위해 최첨단 AI 모델을 활용해야 하지만, 클라우드 기반 대형 언어 모델(LLM)의 높은 비용을 관리하고 데이터 개인정보 보호 규정을 준수해야 합니다.
그렇다면 기업이 예산을 과도하게 늘리거나 민감한 개인정보를 노출하지 않으면서 최첨단 AI를 활용하려면 어떻게 해야 할까요? Cloudera는 이러한 문제를 기회로 전환하는 솔루션을 개발했습니다. 이 솔루션은 민감한 데이터를 기반으로 생성된 합성 데이터와 지식 증류를 활용하여, 비용 효율적이면서 정확하고 규정 준수를 보장하는 AI 시스템을 구축합니다.
이 글에서는 Cloudera AI Studios의 일부인 Cloudera Synthetic Data Generation Studio가 실제 데이터가 부족하거나 민감할 때에도 어떻게 조직이 AI 혁신을 활용할 수 있도록 지원하는지 설명합니다.
활용 사례 및 주요 시사점
활용 사례: Cloudera는 내부 사례를 바탕으로 민감한 데이터를 기반으로 생성된 합성 데이터를 활용한 지식 증류를 통해 데이터 프라이버시와 규정 준수를 유지하면서도 고객 지원 티켓 파이프라인의 성능과 전체 처리량을 눈에 띄게 향상시킨 방법을 소개합니다.
주요 시사점:
데이터 프라이버시로 경쟁력 향상: 합성 데이터를 통해 규제 리스크 없이 혁신을 구현할 수 있습니다.
비용 효율적인 성능 확보: 미세 조정된 소형 모델은 리소스 사용량이 많은 대형 모델보다 뛰어난 성능을 발휘합니다.
다양한 활용 사례에 적용 가능: 동일한 접근법을 부정 행위 탐지부터 맞춤형 고객 서비스까지 다양한 활용 사례에 적용할 수 있습니다.
비즈니스 과제: 데이터 프라이버시를 유지하면서 AI 모델 속도와 정확성 사이의 균형 확보
Cloudera의 고객 지원 팀은 AI 모델을 활용하여 고객 지원 티켓을 실시간으로 분석하고 요약합니다. 시스템은 고객 또는 Cloudera 지원 담당자의 의견을 입력 데이터로 처리합니다. 그 다음에는 각 의견을 분석하고 감정이나 요약과 같은 일련의 분석 데이터를 추출합니다. 이러한 분석 결과는 Cloudera의 고객 경험을 개선하는 데 핵심적인 역할을 합니다.
이 파이프라인에서 처리되는 고객 데이터의 민감성으로 인해 로컬 환경에서 실행되는 모델만 사용할 수 있으며, 어떤 외부 소스와도 고객 데이터를 공유할 수 없습니다.
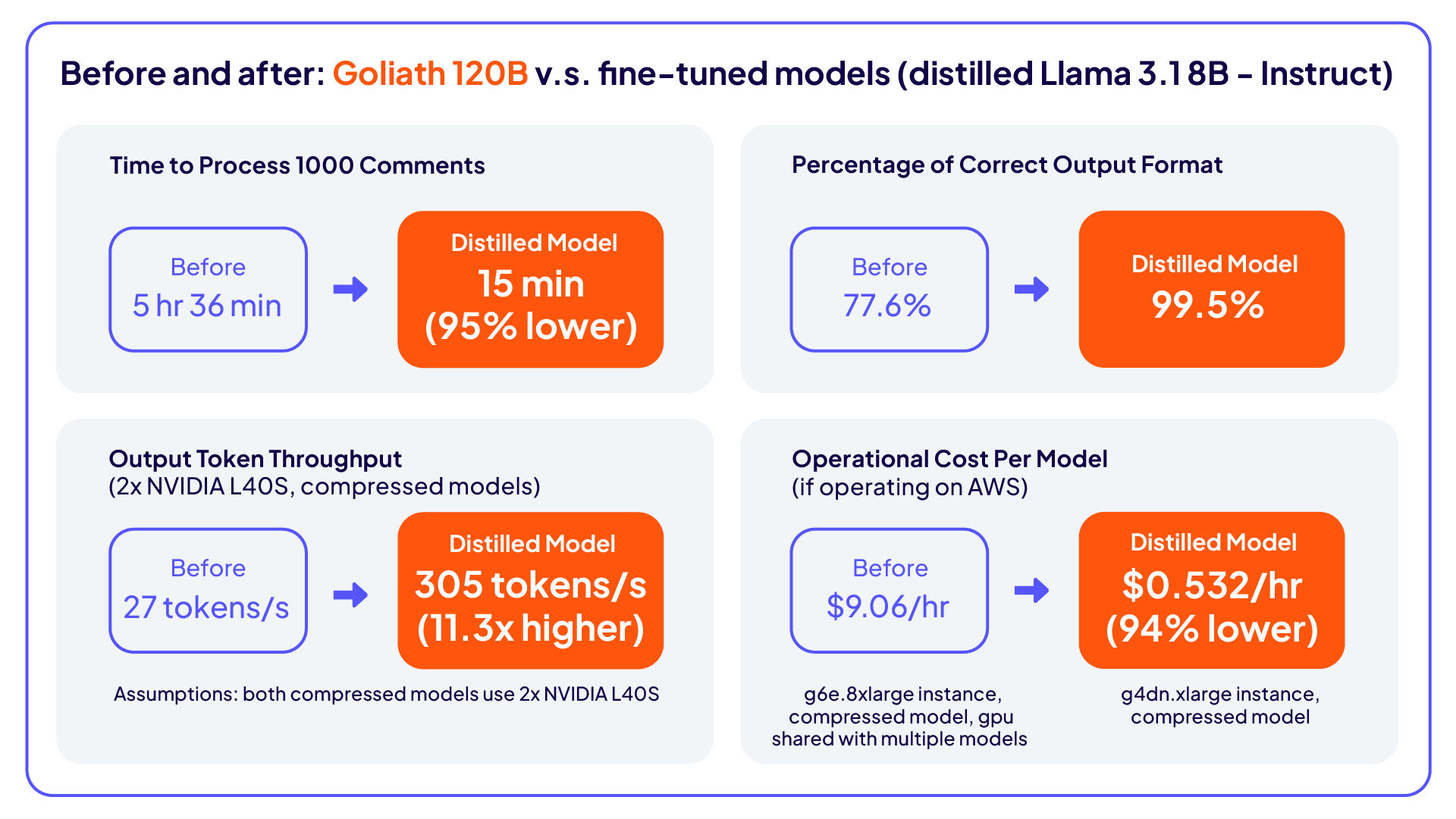
초기에 팀은 의견 분석을 위해 로컬 LLM(Goliath 120B)을 사용했습니다. 이 모델은 기본적인 성능 요구 사항은 충족했지만 처리 속도와 생성 품질 면에서 한계가 있었습니다. 평균적으로 요청 한 건을 처리하는 데 12~15초가 소요되었고, 요청은 30초 간격으로 발생했습니다. 기대 출력 준수율은 77.5%였고, 생성 정확도는 자체 모델에 비해 낮아 확장성과 LLM 성능에 있어 병목 요인으로 작용했습니다.
로컬 대형 LLM(Goliath-120B)을 사용한 경우에는 응답 시간 지연, 비용 증가, 최신 클라우드 기반 모델 대비 낮은 생성 정확도, 그리고 규정 준수 위험과 같은 한계들이 명확히 드러났습니다.
대규모 조직도 이와 마찬가지로 AI의 정확도와 속도 향상을 추구하는 동시에 데이터 노출로 인한 리스크를 최소화해야 하는 까다로운 과제에 직면해 있습니다.
Cloudera의 솔루션: 프라이빗 데이터를 활용한 지식 증류
Cloudera는 개인정보 보호를 핵심 원칙으로 삼아 지식 증류에 접근하는 혁신적인 방법을 적용했습니다.
Cloudera는 규제나 데이터 노출 리스크가 있는 실제 고객 데이터를 모델 학습에 직접 사용하는 대신 Cloudera Synthetic Data Studio라는 로우코드 도구를 활용해 합성 데이터세트를 생성했습니다. Cloudera AI의 이 새로운 로우코드 도구는 기술적 질문, 문제 해결 시나리오 등 실제 고객 상호작용을 모방하면서도 비공개 정보를 전혀 노출하지 않았습니다.
합성 고객 지원 상호작용의 생성은 규제 및 데이터 노출 측면에서 이점을 제공했고, 더 나아가 팀은 이 합성 데이터를 최첨단 클라우드 기반 LLM에 전달하여 가장 성능이 우수한 LLM에서 고객 감정 분석과 같은 인사이트를 추출할 수 있었습니다. 이러한 클라우드 기반 LLM은 대형 로컬 LLM보다 훨씬 정확한 정보 추출이 가능하여, 최첨단 LLM에서 정확한 인사이트를 증류하는 이상적인 소스가 되었습니다.
Cloudera의 합성 데이터 솔루션은 규정 준수 및 프라이버시 위험을 완전히 제거하면서, 기존 대형 로컬 LLM보다도 높은 품질의 합성 데이터를 생성합니다. 이러한 접근 방식 덕분에 기업은 최신 모델에서 소형 LLM으로 지식을 증류할 수 있게 되었고, Goliath-120B와 동일한 문제를 더 낮은 비용과 더 높은 정확도로 해결할 수 있게 되었습니다.
Cloudera의 작업 프로세스
데이터 생성: Cloudera는 Synthetic Data Studio의 데이터 생성 워크플로를 활용하여 Claude Sonnet에 고객 질문과 답변을 생성하도록 지시하는 프롬프트를 작성했습니다. 이 프롬프트는 LLM이 고객 지원 질문과 답변을 생성하고, 어조를 추가하며, 구조를 상세히 설명하도록 지시합니다. 또한 Cloudera는 실제 데이터에서 나타나는 주제 목록(예: Cloudera AI 또는 Cloudera Data Warehouse 고객 지원)을 제공하고, 시드 주제를 활용하여 다양하면서도 실제와 유사한 고객 지원 티켓을 생성하도록 했습니다.
미세 조정: Cloudera는 필터링된 데이터만을 사용하여 데이터를 학습용 데이터와 검증용 데이터로 구분한 후 Claude Sonnet 모델에서 Meta Llama3.1-8B-instruct 모델로 지식을 증류했습니다. 이후 여러 실험을 수행하며, 증류된 LLM의 성능을 극대화할 수 있는 미세 조정 파라미터를 선정했습니다.
평가: Cloudera 팀은 Synthetic Data Studio의 평가 워크플로를 활용하여 LLM이 심사자로서 생성된 데이터의 품질을 평가하도록 지시하는 프롬프트를 작성하고 이를 통해 저품질 샘플을 필터링했습니다.
팀은 인간 평가와 LLM 심사자의 자동 평가를 병행하여 실제 고객 지원 티켓 질문과 답변에 점수를 매겼습니다. Cloudera 팀은 배포된 LLM과 증류된 LLM 간 답변이 상이한 경우에 주목하고, 각 LLM의 승률을 보고했습니다. 또한 평균 실행 시간, 예상 출력 준수율, 모델 배포 비용 측면에서 속도 개선 효과를 측정했습니다.
결과
속도 향상: 처리 시간이 95% 감소했습니다.
출력 구조 개선: 출력 준수율이 77.5%에서 99.5%로 상승했습니다.
LLM 정확도 향상: 소형 증류 LLM(Llama 3.1 8B)과 배포된 Goliath LLM(Goliath 120B)을 비교했을 때, Phi-4를 심사자로 사용한 경우에는 승률이 70% 대 30%, 인간 평가자를 사용한 경우에는 승률이 63% 대 37%였습니다.
비용 및 효율 개선: 소형 증류 LLM은 컴퓨팅 및 메모리 요구량을 줄이면서 실시간 확장성을 높이고 데이터 프라이버시를 유지했으며, 처리량은 11배 향상되었습니다.
위와 같은 결과는 기업이 데이터 프라이버시를 훼손하지 않으면서도 AI 우수성을 달성할 수 있음을 명확히 보여줍니다. 학습 데이터를 합성하고 지식을 증류함으로써, 혁신과 규정 준수 사이의 상충 문제를 피할 수 있습니다.
합성 데이터로 규제 위험 없이 혁신 실현
Cloudera는 지식 증류 접근법을 개발하여 처리 시간을 95% 단축하고, 출력 구조 준수율을 99.5%까지 향상시켰습니다. 또한 증류된 Llama 3.1 8B 모델을 배포하여 이전 Goliath 120B 모델 대비 정확도가 Phi-4 평가 기준 70%, 인간 평가 기준 63% 더 높아졌습니다.
이 방법을 적용한 결과, 민감한 데이터를 직접 사용하지 않아 규정 준수 위험이 사라졌으며 처리량이 11배 증가했습니다. 이는 소형 미세 조정 모델이 리소스 사용량이 많은 대형 모델보다 속도 및 정확성 면에서 더 우수할 수 있음을 보여줍니다.
Cloudera AMP 를 직접 체험해 보고 민감한 합성 데이터를 활용하여 고객 지원 활용 사례에서 대형 모델의 지식을 소형 모델로 증류하는 방법을 확인해 보세요.



