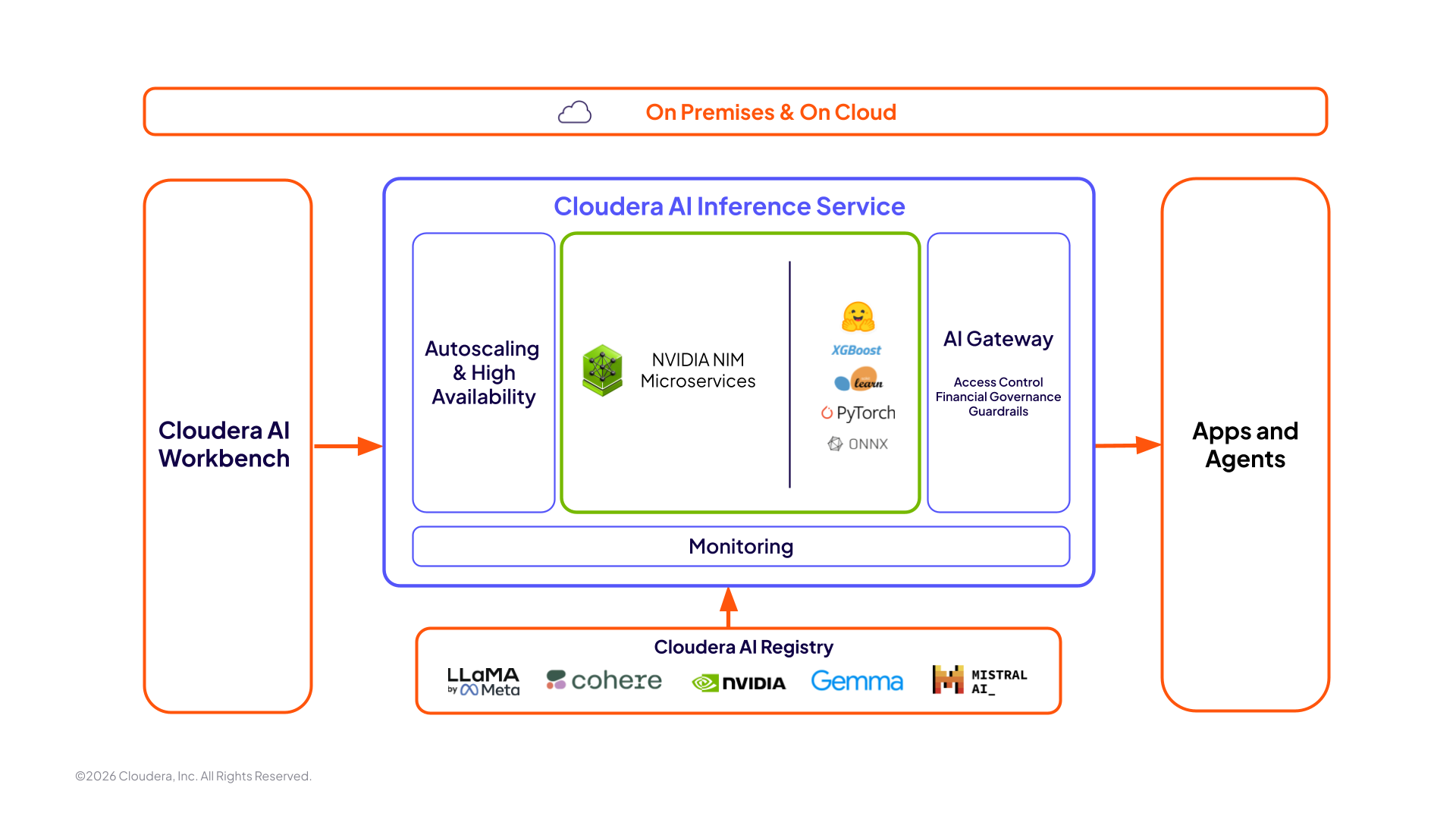
Cloudera AI Inference Service
모델 서빙을 가속화하여 탁월한 속도, 보안, 효율성을 바탕으로 프라이빗 AI 애플리케이션, 에이전트, 어시스턴트를 배포하고 확장합니다.

AI 라이프사이클의 모든 단계를 보호하면서 AI를 개발하고 배포하세요.
NVIDIA NIM 마이크로서비스 기반의 Cloudera AI Inference Service는 최대 36배 빠른 NVIDIA GPU 추론 성능과 CPU에서 약 4배 높은 처리량을 제공하여 AI 관리 및 거버넌스를 퍼블릭 및 프라이빗 클라우드 전반에서 원활하게 통합합니다.
엔터프라이즈 AI 추론을 위한 단 하나의 서비스
원클릭 배포: 환경에 관계없이 모델을 개발 단계에서 프로덕션으로 빠르게 전환합니다.
단일 보안 환경: AI 라이프사이클의 모든 단계를 아우르는 강력한 엔드 투 엔드 보안을 제공합니다.
단일 플랫폼: 모든 AI 요구 사항을 처리하는 단일 플랫폼으로 모든 모델을 원활하게 관리합니다.
원스톱 지원: 하드웨어 및 소프트웨어에 관련된 모든 문의를 통합적으로 지원합니다.
AI Inference Service 주요 기능
AI 추론 서비스 배포 옵션
성능, 보안 또는 제어 기능을 유지하면서 온프레미스 또는 클라우드에서 추론 워크로드를 실행하세요.
클라우드에서의 Cloudera
- 멀티 클라우드 유연성: 퍼블릭 클라우드 전반에 배포하고 에코시스템 종속을 방지하세요.
- 신속한 가치 실현: 별도의 인프라 구축 없이 즉시 추론을 시작하세요. 신속한 실험에 적합합니다.
- 탄력적 확장: 리소스를 0까지 줄이는 자동 확장 기능과 GPU 최적화 마이크로서비스를 통해 트래픽 변동에 유연하게 대응하세요.
온프레미스에서의 Cloudera
- 데이터 주권: 완전한 제어를 유지하세요. 모델, 프롬프트 및 자산을 방화벽 내부에 그대로 유지하세요.
- 외부 네트워크와 분리된 환경에서도 운영 가능: 정부, 의료 및 금융 서비스와 같은 규제 환경을 위해 설계되었습니다.
- 예측 가능하고 낮은 TCO: 고정 요금제를 통해 예기치 않은 비용을 방지하고 토큰 기반 클라우드 API 대비 TCO를 절감하세요.
데모
손쉬운 모델 배포를 직접 경험해 보세요.
강력한 Cloudera 도구로 대규모 언어 모델을 손쉽게 배포하여 대규모 AI 애플리케이션을 효과적으로 관리하는 방법을 확인하세요.

모델 레지스트리 통합:
중앙 집중식 Cloudera AI Registry 리포지토리를 통해 모델을 원활하게 액세스, 저장, 버전 관리 및 운영합니다.
간편한 구성 및 배포: 클라우드 환경 전반에서 모델을 배포하고 엔드포인트를 설정하며 자동 확장 기능을 조정하여 효율성을 높입니다.
성능 모니터링:
지연 시간, 처리량, 리소스 사용률, 모델 상태와 같은 주요 지표를 기반으로 문제를 해결하여 최적화합니다.

Cloudera AI Inference는 NVIDIA의 AI 전문성을 기반으로 데이터의 잠재력을 최대한 활용하고 엔터프라이즈급 보안 기능으로 데이터를 안전하게 보호합니다. 이를 통해 온프레미스 또는 클라우드에서 안정적으로 데이터를 보호하고 워크로드를 실행하는 동시에 유연성 및 거버넌스를 갖춘 효율적인 AI 모델을 배포할 수 있습니다.