Cloudera Data Flow
범용 데이터 분배, 민첩성 및 무한한 확장성을 실현합니다.

효과적인 데이터 분배를 통한 AI 및 분석 가속
Cloudera Data Flow는 Apache NiFi 기반의 클라우드 네이티브 데이터 서비스로, 데이터 이동에 대한 엔드 투 엔드 프로세스를 간소화하여 범용 데이터 배포를 지원합니다.
450개 이상의 중립적 커넥터를 통해 데이터 센터와 클라우드 전반에서 모든 소스의 데이터를 원하는 목적지로 자유롭게 이동합니다.
간소화된 아키텍처로 효율성을 극대화하여 데이터 종속을 방지하고 도구 확산 및 중복 데이터 이동을 감소시킵니다.
데이터 파이프라인 라이프사이클의 모든 단계에서 노 코드 개발자 셀프서비스를 지원하여 한 단계 높은 민첩성을 제공합니다.
Apache NiFi 2.0을 지원하는 유일한 벤더, Cloudera
온프레미스
퍼블릭 클라우드
Kubernetes 오퍼레이터 기반 자체 클러스터 배포 지원
사용 사례
최적의 효율성을 바탕으로 비즈니스 크리티컬 데이터를 실시간 제공합니다.
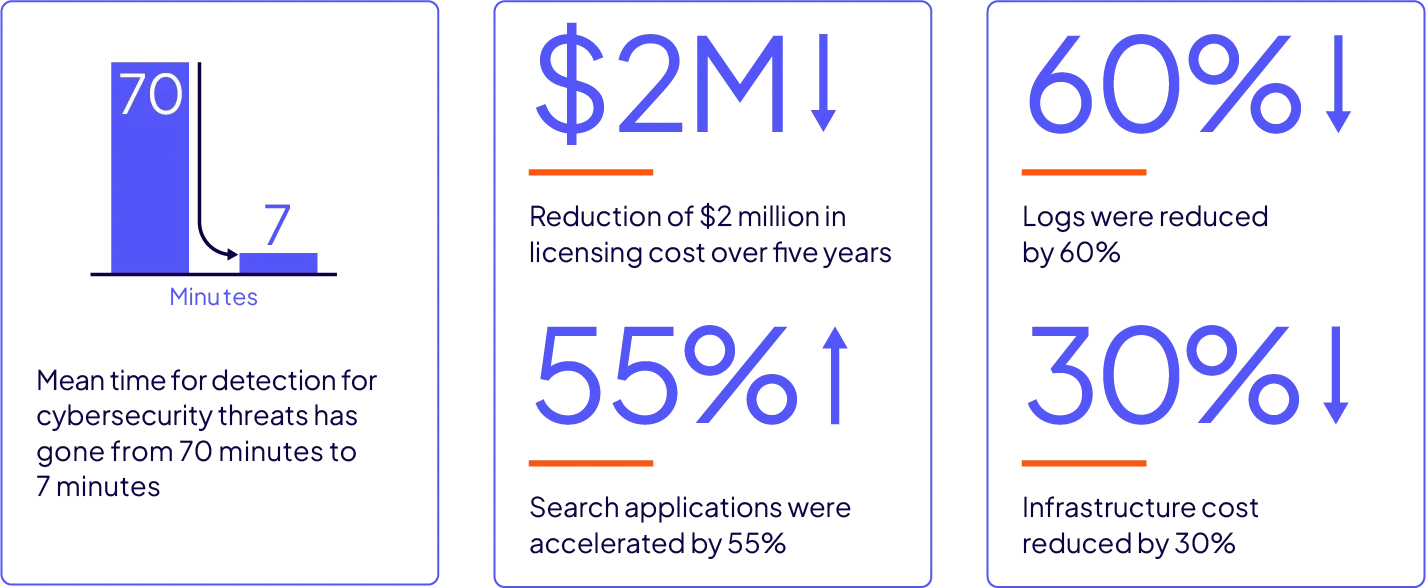
데이터가 발생하는 즉시 처리하고 분석하여 이상 행위, 사이버 공격 및 사기를 방지합니다.
엣지에서 클라우드까지 데이터에 실시간으로 대응하여 피해를 최소화합니다.

신선한 멀티모달 데이터를 AI 에이전트에 제공하고 프롬프트에 실시간 컨텍스트를 추가합니다.
AI 에이전트가 추론 및 자동화 작업을 수행할 때 최신 컨텍스트 및 데이터를 제공합니다.
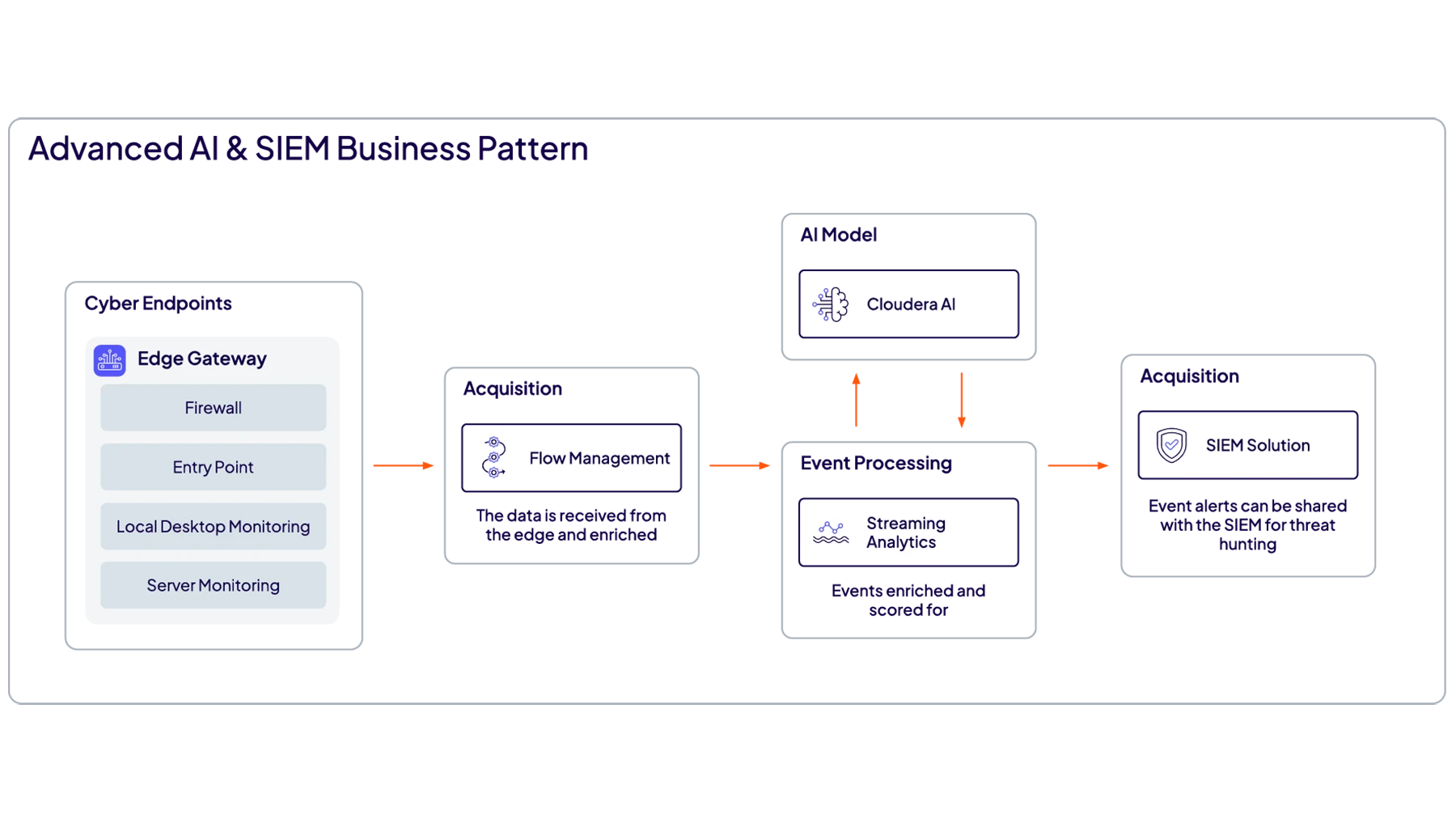
지속적인 가시성, 신속한 의사 결정 및 향상된 운영 복원력을 확보합니다.
비즈니스 운영 전반에서 발생하는 중요 이벤트를 즉시 감지하고 파악하고 대응합니다.

어떤 시스템이나 디바이스에서든 보다 원활한 분석을 위해 모든 유형의 데이터를 수집하고 처리하며 실시간으로 사용자 및 시스템에 전달합니다.
“한 번 작성하고 어디서나 배포할 수 있는” 기능을 통해 일반적인 데이터 흐름을 신속하게 배포하여 비즈니스 성과를 앞당기세요. 버전 관리를 간소화하여 변화하는 비즈니스 및 데이터 요구에 유연하게 대처할 수 있습니다.
서버리스 아키텍처 기반으로 비용을 최적화하고 확장 가능한 운영을 구현합니다. AWS Lambda, Azure Functions 및 Google Cloud Functions를 통해 이벤트 기반 활용 사례 및 실시간 파일 처리를 지원합니다. 직관적인 노코드 UI를 통해 HTTPS 요청으로 트리거되는 마이크로서비스를 구축합니다.
모든 NiFi 플로 배포에 대한 모니터링을 단일 대시보드로 통합합니다. 배포된 플로의 핵심 성능 지표를 추적할 수 있도록 KPI 알림을 설정합니다. 동적으로 확장하여 성능을 유지하고 SLA를 효율적으로 충족합니다.
범용 연결성
데이터 스트림, 데이터베이스, 데이터 레이크, 엔터프라이즈 애플리케이션 등 전용 커넥터를 통해 온프레미스 또는 클라우드의 모든 시스템에 범용적으로 연결하고 업계 표준 프로토콜을 활용합니다.
주요 커넥터
Apache Iceberg
데이터 레이크 및 데이터 웨어하우스
Apache Kafka
데이터 스트림
Delta Lake
데이터 레이크 및 데이터 웨어하우스
Google BigQuery
데이터 레이크 및 데이터 웨어하우스
MongoDB
데이터베이스
Salesforce
엔터프라이즈 애플리케이션
Snowflake
데이터 레이크 및 데이터 웨어하우스

Milvus
생성형 AI
배포 옵션
유연한 배포 옵션으로 장소에 관계없이 모든 데이터를 사용
클라우드에서의 Cloudera
클라우드 기반 Cloudera의 일부로 Data Flow를 배포하여 간소화된 관리와 탄력성을 실현합니다.
온프레미스에서의 Cloudera
Cloudera Flow Management의 일부로 NiFi 플로를 배포하여 지연 시간을 최소화하고 데이터 및 리소스에 대한 제어를 극대화합니다.
Kubernetes 오퍼레이터로 배포
Cloudera Flow Management Operator for Kubernetes를 독립적으로 배포하여 가치 실현 시간을 효과적으로 단축합니다.




{kind=link}
더 많은 제품 살펴보기
데이터가 어디에 있든 실시간 정형 데이터와 비정형 데이터를 수집, 처리 및 분석하여 즉각적인 인사이트 도출, 실행 및 AI 활용이 가능합니다.