Cloudera Streaming
Apache Kafka 및 Apache Flink의 강력한 기능을 활용해 고성능 실시간 서비스 및 애플리케이션을 구축하세요.

개요
실시간 애플리케이션 구축을 위한 기반
Cloudera Streaming은 미션 크리티컬 애플리케이션을 위해 설계되었습니다. Apache Kafka 및 Apache Flink를 활용한 실시간 데이터 처리로 초당 수백만 건의 이벤트를 낮은 지연 시간으로 처리하며 일관성을 보장합니다.
팀이 실시간 ML 모델 및 고급 예측 분석을 위한 신뢰성 높은 파이프라인을 쉽게 구축하도록 지원하여 애플리케이션 개발 속도를 높입니다.
온프레미스 또는 클라우드 환경 전반에서 일관되고 안전하며 거버넌스가 적용된 방식으로 스트리밍 애플리케이션을 개발, 테스트 및 배포합니다.
어디서나 최적의 성능과 확장성을 기반으로 더 빠르고 안전한 데이터 관리 및 분석 애플리케이션을 구축합니다.
사용 사례
비즈니스를 강화하는 애플리케이션을 구축하세요.
-
실시간 부정 행위 탐지
트랜잭션 스트림을 실시간으로 분석하는 마이크로서비스를 구축합니다.
-
동적 고객 경험
상호작용 데이터가 생성되는 즉시 이를 기반으로 작동하는 이벤트 기반 애플리케이션을 구축합니다.
-
예측 유지보수 및 산업 공정 최적화
연결된 디바이스에서 발생하는 대용량 데이터를 수집하고 분석하는 애플리케이션을 구축합니다.
-
엔터프라이즈급 보안
확장된 Cloudera 플랫폼과의 통합을 통해 데이터 라이프사이클 전반을 안전하게 관리하고 거버넌스를 적용합니다.
-
실시간 부정 행위 탐지
트랜잭션 스트림을 실시간으로 분석하는 마이크로서비스를 구축합니다.
-
동적 고객 경험
상호작용 데이터가 생성되는 즉시 이를 기반으로 작동하는 이벤트 기반 애플리케이션을 구축합니다.
-
예측 유지보수 및 산업 공정 최적화
연결된 디바이스에서 발생하는 대용량 데이터를 수집하고 분석하는 애플리케이션을 구축합니다.
-
엔터프라이즈급 보안
확장된 Cloudera 플랫폼과의 통합을 통해 데이터 라이프사이클 전반을 안전하게 관리하고 거버넌스를 적용합니다.

Kafka의 보장된 메시지 전달 및 Flink의 상태 기반 처리를 활용해 복잡하고 끊임없이 정교해지는 사기 위협을 분석하고 대응합니다.
상태, 컨텍스트 및 복합 이벤트 처리를 지원하는 고급 애플리케이션을 개발해 실시간 모델 평가를 수행합니다.
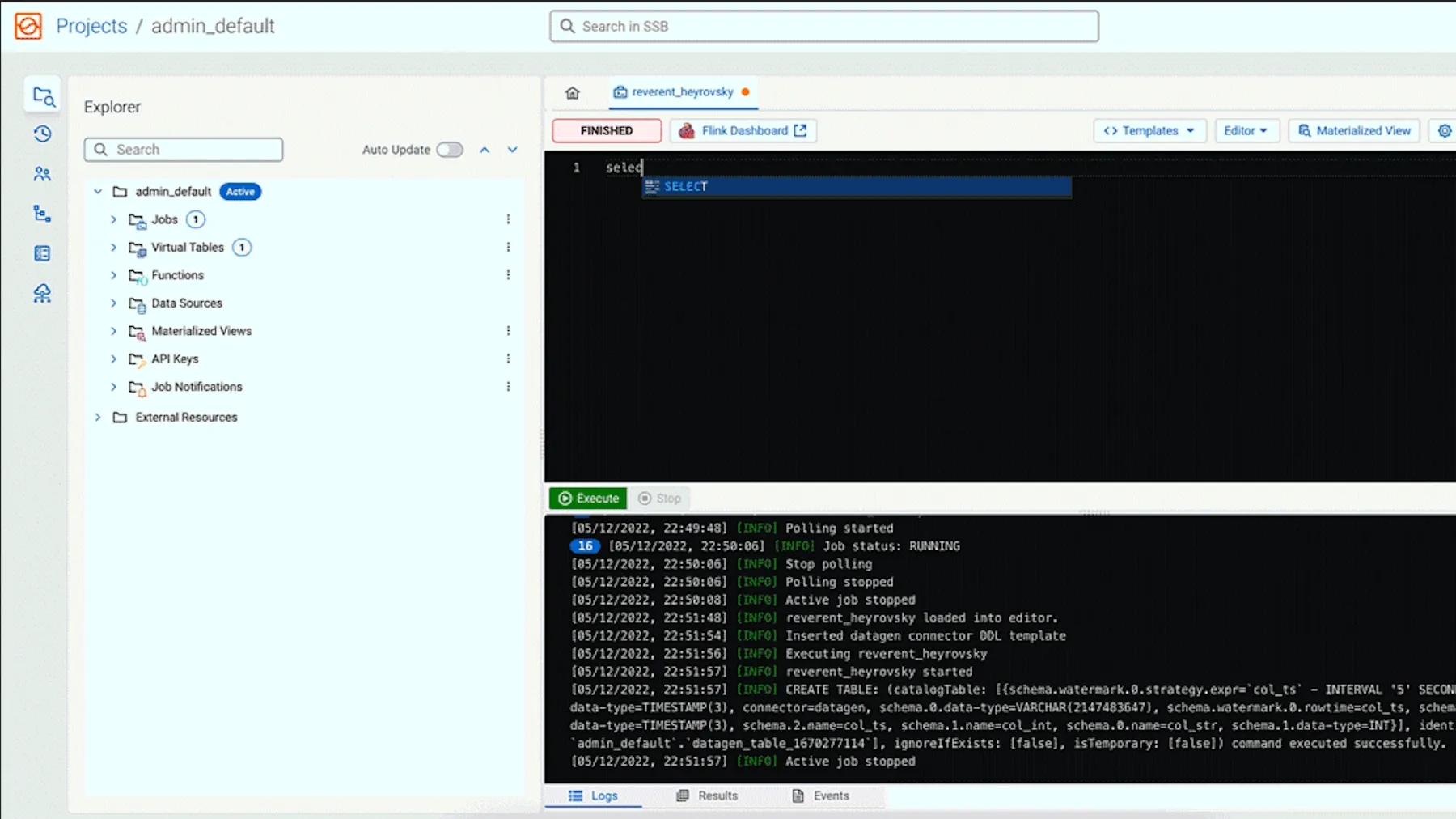
Cloudera SQL Stream Builder를 활용해 즉각적인 오퍼, 동적 추천 및 선제적 서비스 애플리케이션을 구현합니다.
분석가가 실시간 Flink 스트림에 SQL을 적용해 고객 개인화를 실행하고 즉각적으로 차선책을 제안할 수 있도록 지원합니다.

복잡한 IoT 스트림을 처리하고 고장 징후를 식별하며 자동 대응을 트리거합니다.
Kafka 및 Flink용 오퍼레이터는 배포 및 확장을 자동화해 팀이 애플리케이션 로직에 더욱 집중하도록 지원합니다.
Cloudera SDX *는 모든 전송 중인 데이터를 보호해 데이터 품질 및 일관성을 보장합니다.
운영 팀에 포괄적인 모니터링 도구를 제공해 데이터 액세스 및 거버넌스를 제어할 수 있도록 합니다.
Flink SQL 작업을 구축, 테스트 및 관리할 수 있는 직관적인 인터페이스를 제공합니다. 개발 속도를 높이고 더 다양한 기술 사용자가 강력한 스트리밍 애플리케이션을 구축하도록 지원합니다.
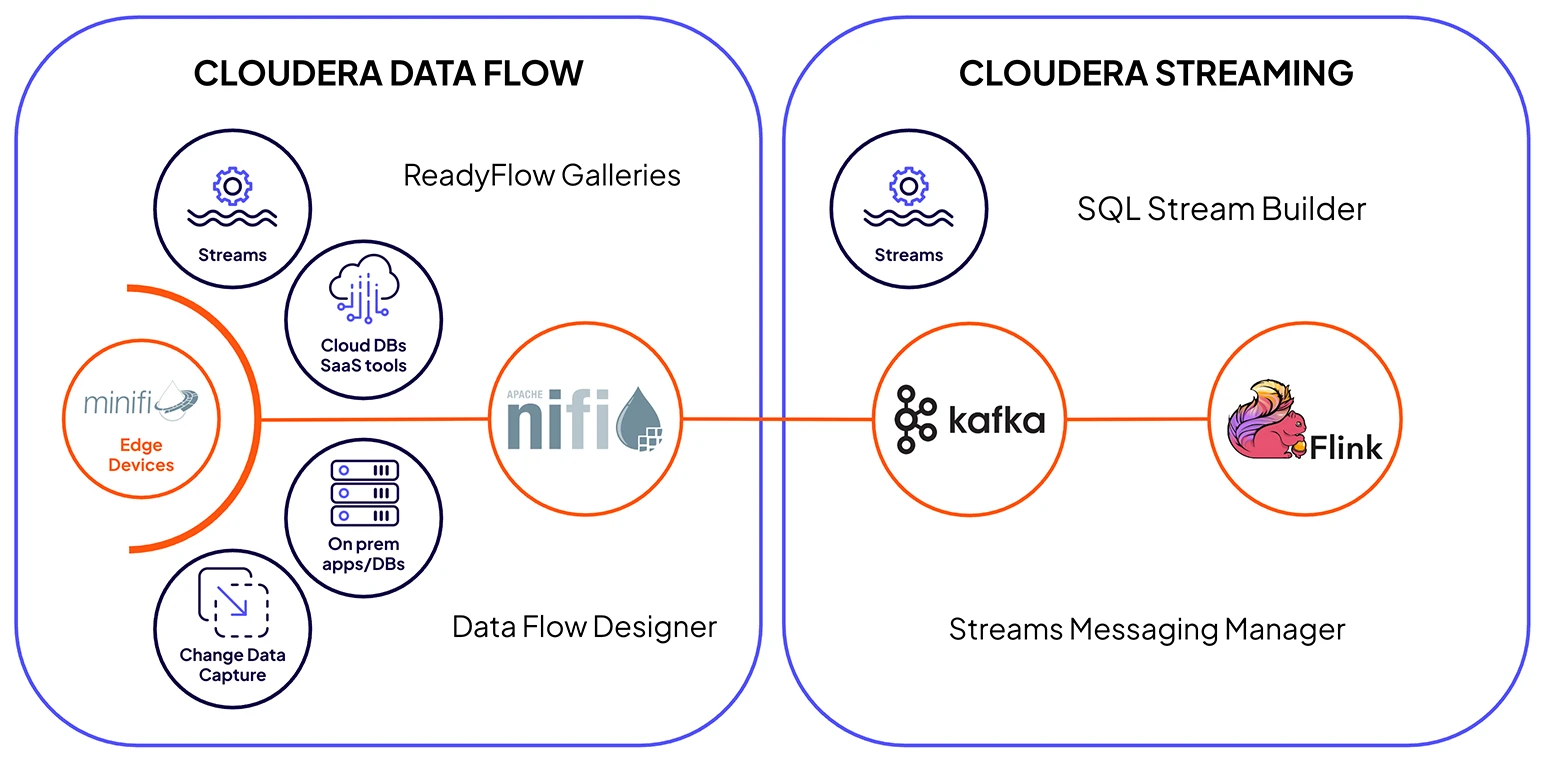
업계를 선도하는 스트림 처리 엔진인 Apache Flink 기반의 Cloudera Streaming Analytics 플랫폼은 미션 크리티컬 애플리케이션에 필요한 성능 및 복원력을 제공합니다.
Apache Kafka 기반의 Cloudera Streams Messaging은 실시간 애플리케이션을 위한 강력하고 확장 가능하며 안전한 메시징 백본으로, 가장 까다로운 개발 워크로드를 지원하는 안정적인 데이터 전송 계층을 제공합니다.
Cloudera Streaming은 Cloudera Data Flow와 결합해 NiFi 기반의 안전한 수집, Kafka 기반의 안정적 전송 및 Flink 기반의 실시간 처리를 통해 데이터 라이프사이클 전반을 아우르는 통합 엔터프라이즈급 구성 요소를 제공합니다.
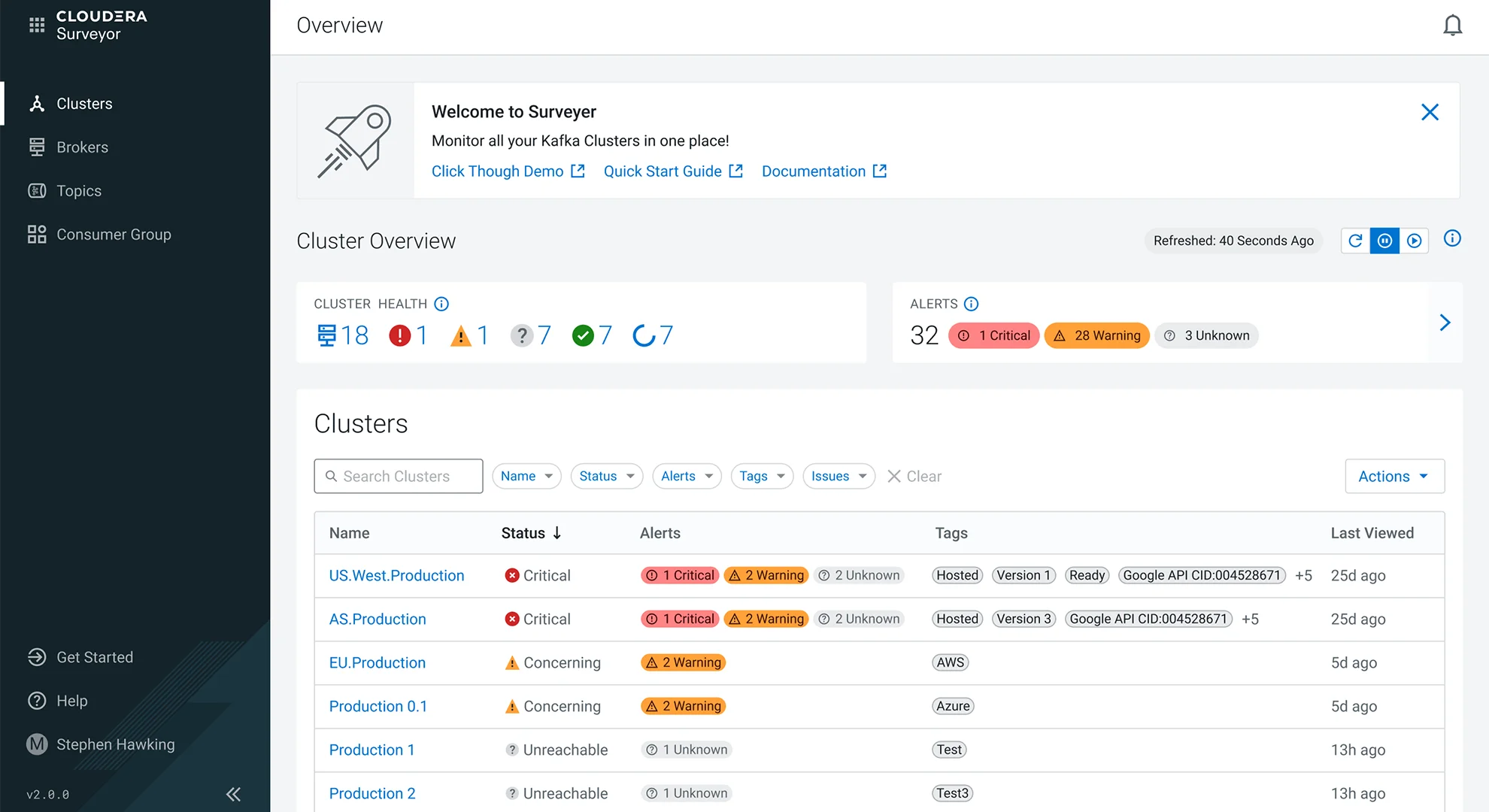
Cloudera Surveyor는 Kubernetes에서 실행되는 Kafka를 한눈에 모니터링할 수 있는단일 화면을 제공해 운영을 간소화하고 애플리케이션 데이터 백본의 안정성을 보장합니다. Schema Registry는 데이터 스키마를 관리할 수 있는 중앙 집중식 버전 관리 저장소를 제공합니다.



배포 옵션
어디서나 구축하고 배포할 수 있는 유연한 기반을 제공합니다.
퍼블릭 클라우드 애플리케이션용
팀이 원하는 퍼블릭 클라우드 플랫폼에서 실시간 애플리케이션을 구축하고 확장하도록 지원합니다.
온프레미스 애플리케이션용
프라이빗 클라우드의 일부로 배포해 개발자가 지연 시간과 리소스를 최대한 제어할 수 있습니다.
Kubernetes 오퍼레이터로 배포
표준을 준수하는 Kubernetes 클러스터에서 DevOps 팀이 Flink 및 Kafka를 독립적으로 제공할 수 있도록 지원하여 민첩성과 셀프 서비스를 극대화합니다.