Apache Tez
Hadoop에서 YARN 기반의 데이터 처리 애플리케이션을 위한 프레임워크
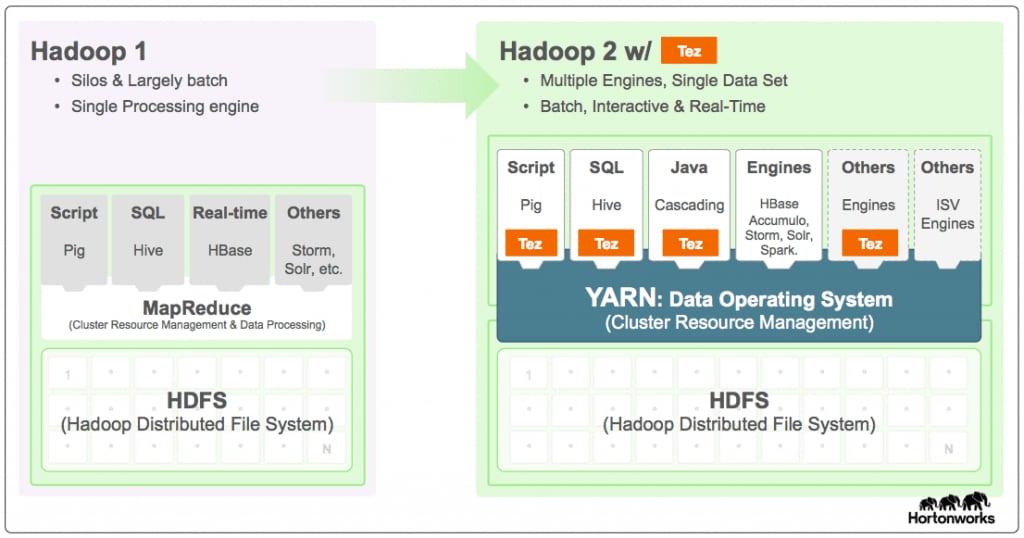
Apache™ Tez는 고성능 배치 및 대화형 데이터 처리 애플리케이션을 구축하기 위한 확장 가능한 프레임워크이며, Apache Hadoop에서 YARN을 통해 조정됩니다. Tez는 속도를 획기적으로 향상시킴으로써 MapReduce 패러다임을 개선하는 동시에, MapReduce가 페타바이트 단위의 데이터로 확장하는 기능을 유지합니다. Apache Hive 및 Apache Pig와 같은 중요한 Hadoop 에코시스템 프로젝트는 Apache Tez를 사용하지만, 보다 광범위한 Hadoop 에코시스템을 위해 개발된 타사 데이터 액세스 애플리케이션의 사용도 점점 늘어나고 있습니다.
Tez를 포함한 Hive
SQL-In-Hadoop의 사실상 표준인 Apache Hive 는 페타바이트 규모의 배치 및 대화형 쿼리 모두에 최적입니다. Hive는 Tez를 포함하고 있어 복합 SQL 문을 성능, 처리량, 확장성 균형을 최적으로 유지하는 고도로 최적화된 특수 데이터 처리 그래프로 변환할 수 있습니다. Apache Tez의 혁신은 Stinger Initiative를 통해 제공되는 많은 Hive 성능 향상을 이끌었고, 이 혁신은 조직 44곳의 엔지니어 145명의 엔지니어가 기여로 탄생한 폭넓은 커뮤니티 성과입니다. Tez를 통해 대화형 Hive가 가능합니다.

Tez가 수행하는 작업
Apache Tez는 개발자 API 및 프레임워크를 제공하여 대화형 워크로드와 배치 워크로드를 연결하는 네이티브 YARN 애플리케이션을 작성합니다. 이로써 데이터 액세스 애플리케이션은 수천 개의 노드에서 페타바이트 단위의 데이터를 사용할 수 있습니다. Apache Tez 구성요소 라이브러리를 통해 개발자는 Apache Hadoop YARN과 기본적으로 통합되고 혼합 워크로드 클러스터 내에서 성능이 뛰어난 Hadoop 애플리케이션을 제작할 수 있습니다. Tez는 확장 및 내장 가능하기 때문에 매우 최적화된 데이터 처리 애플리케이션을 목적에 맞게 자유롭게 표현하여 MapReduce 및 Apache Spark와 같은 최종 사용자용 엔진에 비해 이점이 있습니다. 또한 Tez는 사용자가 복잡한 계산을 데이터 흐름 그래프로 표현할 수 있는 맞춤 가능 실행 아키텍처를 제공하여 데이터에 대한 실제 정보와 이 데이터를 처리하는 데 필요한 리소스를 토대로 동적 성능 최적화를 허용합니다.
Tez 작동 원리
Apache Tez의 Hadoop 데이터 처리 개선은 Apache Hive 및 Apache Pig에서 얻은 이점을 대폭 확장합니다. 이 프로젝트에서는 대화형 워크로드를 위한 YARN과의 진정한 통합 표준을 마련했습니다. Apache Tez가 핵심 작업을 완료하는 방식에 대해 다음의 간략한 설명을 읽어보세요.
처리 로직을 표현, 모델링 및 실행
Tez는 애플리케이션 로직을 나타내는 그래프 정점과 데이터의 이동을 나타내는 엣지를 사용하여 데이터 흐름 그래프로 데이터 처리를 모델링합니다. 풍부한 데이터 흐름 정의 API를 통해 사용자는 복잡한 쿼리 로직을 직관적으로 표현할 수 있습니다. 이 API는 Apache Hive 및 Apache Pig와 같은 높은 수준의 선언적 애플리케이션에서 생성된 쿼리 계획과 잘 맞습니다.
입력, 프로세서 및 출력 모듈 간의 상호작용 모델링
Tez는 데이터 흐름 그래프의 각 정점에서 실행 중인 사용자 로직을 입력, 프로세서 및 출력 모듈의 구성으로 모델링합니다. 입력 및 출력은 데이터 형식뿐 아니라 데이터 읽기나 쓰기 방법을 결정합니다. 프로세서에서는 데이터 변환 로직을 보유합니다. Tez는 데이터 형식을 적용하지 않으며 입력, 프로세서 및 출력 형식이 서로 호환되기만 하면 됩니다.
그래프를 동적으로 재구성
분산된 데이터 처리는 동적이며 최적의 데이터 이동 방법을 미리 파악하기 어렵습니다. 런타임 중에 추가 정보를 사용할 수 있으므로, 실행 계획을 더욱 최적화할 수 있습니다. 따라서 Tez는 성능 및 리소스 활용도를 최적화하기 위해 런타임 정보를 수집하고 데이터 흐름 그래프를 동적으로 변경할 수 있는 플러그형 정점 관리 모듈을 지원합니다.
성능과 리소스 관리 최적화
YARN은 클러스터 용량 및 로드를 기준으로 Hadoop 클러스터의 리소스를 관리합니다. Tez 실행 엔진 프레임워크는 YARN의 리소스를 효율적으로 획득하고 불필요하게 작업이 중복되지 않도록 파이프라인의 모든 구성요소를 재사용합니다.
DAG(directed acyclic graphs) 정의용 API
Tez는 데이터 처리 DAG를 표현하기 위한 단순 Java API를 정의합니다. API에는 세 가지 구성요소가 있습니다.
- DAG – 전체 작업을 정의합니다. 사용자는 각 데이터 처리 작업별로 DAG 개체를 만듭니다.
- Vertex - 사용자 로직을 실행하는 데 필요한 리소스 및 환경을 정의합니다. 사용자는 작업의 각 단계별로 Vertex 개체를 만들고 DAG에 추가합니다.
- Edge – 제작자와 소비자 정점 연결을 정의합니다. 사용자는 Edge 개체를 만들고 이 개체를 사용하여 제자와 소비자 정점을 연결합니다.
컨테이너 재사용
Tez는 작업을 개별 작업으로 나누는 기존 Hadoop 모델을 따르며, 이 모델은 모두 사용자 대신 YARN을 통해 프로세스로 실행됩니다. 이 모델의 경우 프로세스 시작 및 초기화, 스트래글러 처리, YARN 리소스 관리자를 통한 각 컨테이너 할당에 따른 고유한 비용이 수반됩니다.