Apache Hadoop 에코시스템
Hadoop은 오픈 소스 구성 요소가 모인 에코시스템으로, 기업이 데이터를 저장, 처리, 분석하는 방법에 근본적인 변화를 가져옵니다. 기존 시스템과 달리, Hadoop을 사용하면 여러 유형의 분석 워크로드를 업계 표준 하드웨어에서 대규모로 동시에 동일한 데이터에 실행할 수 있습니다. Cloudera의 오픈 소스 플랫폼인 CDH는 Hadoop과 관련 프로젝트 중 세계에서 가장 인기 있는 배포입니다(Cloudera Enterprise 구독으로 지원 제공).
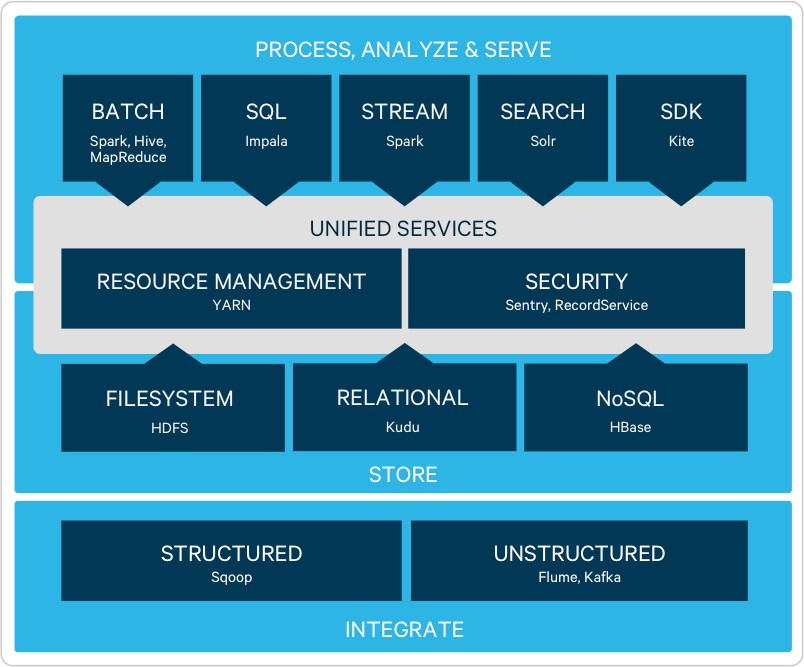
스토어
Hadoop은 (HDFS 파일 시스템에 기초하여) 무한히 확장 가능한 유연한 아키텍처입니다. Hadoop을 사용하는 기관은 데이터의 양 및 유형을 불문하고 업계 표준 하드웨어에 설치된 하나의 오픈 소스 플랫폼에서 데이터를 저장, 분석할 수 있습니다.


프로세스
기존 시스템/애플리케이션과 신속히 통합되어 대량 부하 처리(Apache Sqoop) 또는 스트리밍(Apache Flume, Apache Kafka)을 통해 Hadoop 안팎으로 데이터를 이동합니다.
배치(MR2) 또는 고속 메모리(Apache Spark™) 처리를 위한 여러 데이터 액세스 옵션(Apache Hive, Apache Pig)을 사용하여 규모에 맞게 복합 데이터를 변환합니다. Spark Streaming을 통해 클러스터에서 스트리밍 데이터가 도착하면 처리합니다.
발견
Hadoop용 데이터 웨어하우스 Apache Impala를 통해 분석가들은 정확도 높은 데이터와 즉시 상호 작용할 았습니다. Impala는 BI 품질의 SQL 성능 및 기능과 더불어 모든 주요 BI 툴과의 호환성을 제공합니다.
Hadoop과 Apache Solr을 통합한 Cloudera Search를 사용하면 분석 전문가들은 데이터의 규모 및 형식과 관계없이 패턴 발견 속도를 높일 수 있습니다. 특히, Impala와 결합하면 더욱 속도가 빨라집니다.


모델
분석가와 데이터 과학자는 Hadoop을 통해 Apache Spark™와 같은 오픈소스 프레임워크뿐만 아니라 파트너 기술을 결합하여 고급 통계 모델을 자유롭게 개발하고 반복할 수 있습니다.
Serve
Hadoop, Apache HBase의 분산된 데이터 스토어는 온라인 애플리케이션에 필요한 빠른 랜덤 읽기/쓰기("빠른 데이터")를 지원합니다.

CDH: 오픈 소스 및 오픈 표준 기반
세계에서 가장 많이 사용하는 Hadoop 배포, CDH는 Cloudera의 100% 오픈 소스 플랫폼입니다. 무제한 데이터를 저장, 처리, 발견, 모델링, 서비스하기 위한 모든 주요 Hadoop 에코시스템을 포함하며, 안정성과 신뢰성에서 가장 높은 수준의 기업 표준을 준수하도록 설계되었습니다.
CDH는 장기 아키텍처에 대해 100% 개방형 표준을 따릅니다. 또한 Hadoop에서 개방형 표준의 기본 큐레이터인 Cloudera는 플랫폼(예: Apache Spark™, Apache HBase, Apache Parquet)에 새로운 오픈소스 솔루션을 도입해오며, 이러한 시도들은 전체 에코시스템에서의 채택으로 이어져왔습니다.
